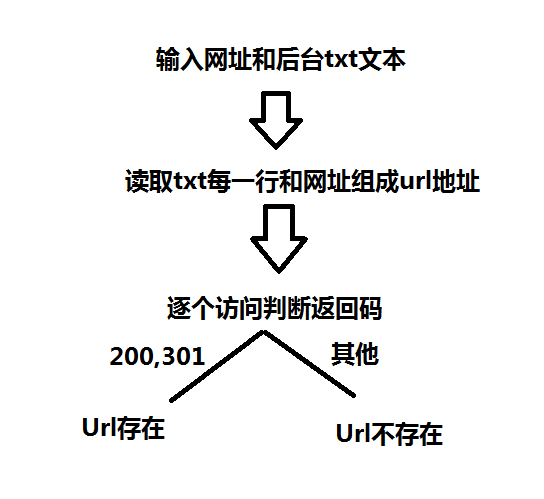
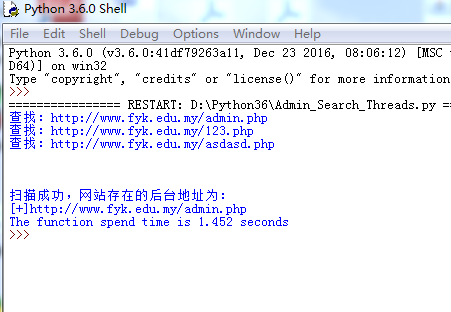
''' Program:网站后台扫描工具 Function:通过字典扫描网站后台 Time:2017/10/13 Author:Walks 个人博客:http://www.bywalks.com ''' import urllib.request import time import threading #与用户交互,也可用命令行 url = input("输入你要扫描到的网址:") txt = input("输入字典(php.txt):") #保存存在的后台地址 open_url = [] all_url = [] #建立线程列表 threads = [] #从字典中读取每一行与url组合,然后添加到all_url def search_url(url,txt): with open(txt,'r') as f: for each in f: each = each.replace('\n','') urllist = url + each all_url.append(urllist) #处理URL def handle_url(urllist): print("查找:"+urllist+'\n') try: req = urllib.request.urlopen(urllist) #判断返回码 if req.getcode()==200: open_url.append(urllist) if req.getcode()==301: open_url.append(urllist) except: pass #主函数 def main(): search_url(url,txt) #多线程处理 for each in all_url: t = threading.Thread(target = handle_url,args=(each,)) threads.append(t) t.start() #线程等待 for t in threads: t.join() #扫描成功和不成功的回显 if open_url: print("扫描成功,网站存在的后台地址为:") for each in open_url: print("[+]"+each) else: print("没有扫描到网站后台(可能是字典不够给力)") if __name__=="__main__": #判断程序运行时间 start = time.clock() main() end = time.clock() print("The function spend time is %.3f seconds" %(end-start))
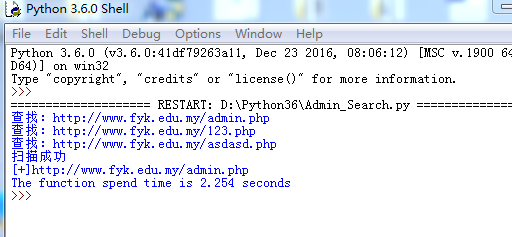
#导入各种库,urllib.request是用来打开和阅读urls,等同于Python2.x的urllib2 #用来时间延时,time.sleep(1),就是延时一秒 #threading用来实现多线程 import urllib.request import time import threading #与用户交互,也可用命令行argparse url = input("输入你要扫描到的网址:") txt = input("输入字典(php.txt):") #保存存在的后台地址 open_url = [] all_url = [] #建立线程列表 threads = [] #从字典中读取每一行与url组合,然后添加到all_url def search_url(url,txt): with open(txt,'r') as f: for each in f: each = each.replace('\n','') urllist = url + each all_url.append(urllist) #处理URL def handle_url(urllist): print("查找:"+urllist+'\n') #try,防出错 try: #利用urlopen打开url req = urllib.request.urlopen(urllist) #判断返回码,如果为200或者301,则该网页存在,把该url加入到open_url if req.getcode()==200: open_url.append(urllist) if req.getcode()==301: open_url.append(urllist) except: pass #主函数 def main(): search_url(url,txt) #多线程 for each in all_url: #建立线程对象 t = threading.Thread(target = handle_url,args=(each,)) #把线程对象加入到线程列表中 threads.append(t) #线程开始 t.start() #线程等待(给每一个线程) for t in threads: t.join() #扫描成功和不成功的回显 if open_url: print("扫描成功,网站存在的后台地址为:") for each in open_url: print("[+]"+each) else: print("没有扫描到网站后台(可能是字典不够给力)") if __name__=="__main__": #判断程序运行时间 #start为程序还没开始的时间,end为程序运行结束的时间 start = time.clock() main() end = time.clock() print("The function spend time is %.3f seconds" %(end-start))