前言
在第一篇文章写完之后,由于网站备案,所以没有写Scrapy框架的知识,后面的二三四都是在其他PT发了之后转回来的文章,下面来继续谈谈Scrapy框架。Scrapy框架很强大,在学WEB安全方面的话,也是挺有用的,例如写一个批量POC脚本,爬取些网站的信息,都可以用爬虫上面的知识去解决,而Scrapy,正是爬虫上面一个比较强大的框架。
框架概览
下面是一张Scrapy框架的架构图,从Spiders开始,Item Pipeline结束
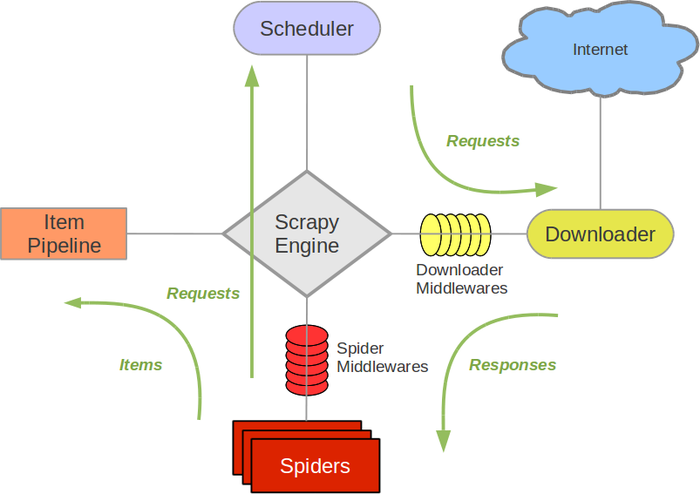
爬取流程
上图的爬取流程为
Spiders把Url发给Scheduler(调度器)
调度器发送Requests给DownLoader
返回Response(也就是爬取网页的HTML)给Spiders
从HTML中提取我们需要的数据(Item内)
传送给Item Pipeline(数据处理器)
目录结构简析
当我们开始一个建立一个Scrapy项目的时候,例如Scrapy startproject FirstProject(建立第一个Scrapy爬虫目录,FirstProject为文件名)
1 | FirstProject/ |
下面说一下每一个py文件的作用。我们爬取一个网站的过程是:访问URL -> 下载访问地址-> 提取数据-> 处理数据
items.py:建立一个存放我们想提取的数据的类
spiders/spider.py:下载URL,并且提取数据放入刚才建立的存放数据的类
pipelines:处理数据(保存等)
settings.py:配置文件(等同于软件的设置)