前言 说完理论,总要说说实战,下面说的就是爬取我的个人博客文章标题,链接,访问者等的实战内容
爬取前奏 我们在开始我们的爬虫之前,第一步要做的是什么?当然是分析网站,构思爬取全过程了。
所以,一开始说的就是爬取思路。
对我的Walks个人博客爬取思路:知道我们要爬取什么-》定位要爬取的元素-》访问文章页-》下载HTML-》提取目标数据-》处理爬取数据
代码实现和分析 Items.py 1 2 3 4 5 6 7 8 9 10 11 12 import scrapy #定义一个存储数据的类,用来存储数据 class MyblogcontentItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #pass #要存储的数据,标题,时间,地址,访问量 title = scrapy.Field() time = scrapy.Field() address = scrapy.Field() visites = scrapy.Field()
Spiders/Walks_Spider.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #encoding=utf-8 #导入爬虫类 import scrapy #导入我们刚才建立的存储数据的类 from MyblogContent.items import MyblogcontentItem class WalksSpider(scrapy.Spider): #唯一标识符 name = "Walks" #允许的域名(只可以从这个域名中爬取) allowed_domains = ['bywalks.com'] #开始爬取的地址 start_urls = [ "http://www.bywalks.com" ] #对爬取的数据(HTML)进行提取 def parse(self,response): #调用Selector,sel就是返回的HTML sel = scrapy.selector.Selector(response) #定位爬取数据 sites = sel.xpath("//div[@id='kratos-blog-post']/div/div/section/article") items = [] for site in sites: item = MyblogcontentItem() #从HTML中提取数据 item["title"] =site.xpath("div/div[@class='kratos-post-inner-new']/header/h2/a/text()").extract() item["time"] = site.xpath("div/div[@class='kratos-post-meta-new']/span[1]/a[1]/text()").extract() item["address"] =site.xpath("div/div[@class='kratos-post-meta-new']/span[1]/a[1]/@href").extract() item["visites"] = site.xpath("div/div[@class='kratos-post-meta-new']/span[2]/a[1]/text()").extract() items.append(item) return items
pipelines.py 1 2 3 4 5 6 7 8 9 10 11 12 class MyblogcontentPipeline(object): #对提取出来的数据进行存储 def process_item(self, item, spider): #打开Walks.json文件,不存在就新建 with open('Walks.json','a+') as f: #写入我们爬取的数据 f.write("title = "+str(item["title"])+'\n') f.write("time = "+str(item["time"])+'\n') f.write("address = "+str(item["address"])+'\n') f.write("visites = "+str(item["visites"])+'\n\n') #返回item,给下一个处理函数处理(如果有的话) return item
sittings.py 1 2 3 4 5 6 7 8 9 10 11 12 13 OT_NAME = 'MyblogContent' SPIDER_MODULES = ['MyblogContent.spiders'] NEWSPIDER_MODULE = 'MyblogContent.spiders' #上面都是直接生成了的,不用添加 #下面使我们自己需要添加的代码,意思就是当我们提取了所需要的数据之后,把数据传入Pipeline里面进行处理,也就是我们上面的py文件 #为什么要添加呢?因为pipeline不是一个爬虫所必须的功能,我们可以自己加也可以不加,所以当需要的时候,我们需要设置下 ITEM_PIPELINES = { 'MyblogContent.pipelines.MyblogcontentPipeline':300 } #是否遵循网站robots.txt的规则 ROBOTSTXT_OBEY = False
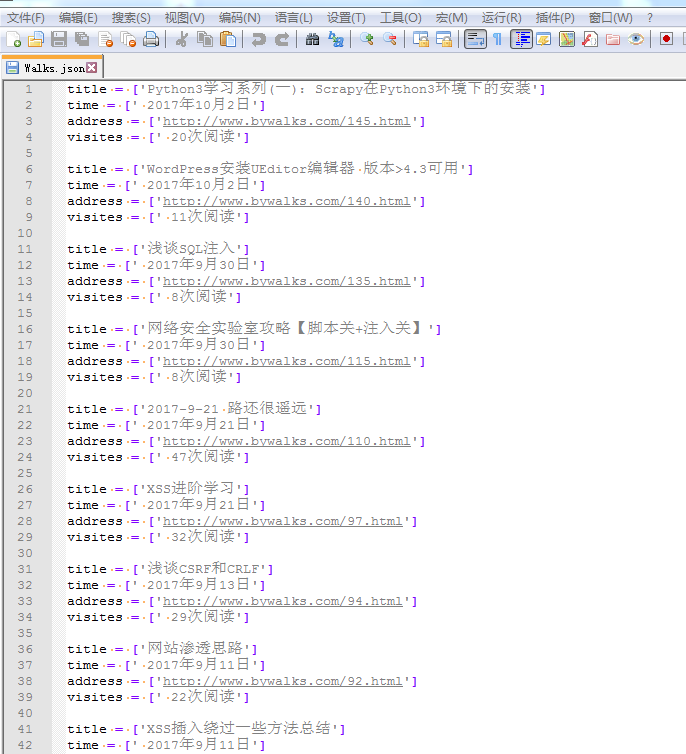
最后附带一张爬取的数据图片
Author:
Bywalks
Permalink:
http://bywalks.com/2017/10/22/python3-study-06/
License:
Copyright (c) 2022 CC-BY-NC-4.0 LICENSE
Slogan:
Do you believe in DESTINY ?